Detecting when LLMs are Uncertain
Thariq Shihipar - · 7 min read
This post tries to explain the new reasoning techniques developed by XJDR in a new project called Entropix.
Entropix attempts to improve reasoning in models through being smarter at sampling during moments of uncertainty.
A big caveat, there have been no large scale evals yet for Entropix, so it’s not clear how much this helps in practice. But it does seem to introduce some promising techniques and mental models for reasoning.
Uncertainity at a glance
Sampling is the process of choosing which token from the distribution of possible tokens (the logits) that a LLM chooses. You can tell how confident a model is in its predictions by looking at that distribution.
This is a confident model prediction for the next token:
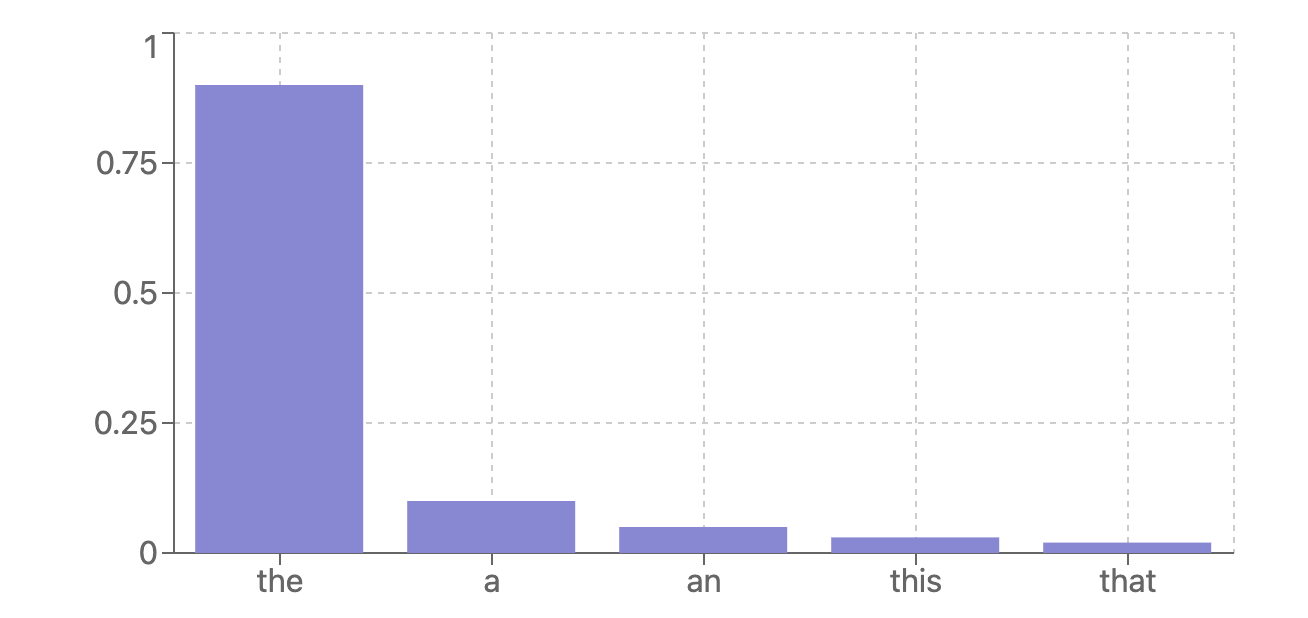
But in reality, models are not always so sure of their predictions. You will often run into cases where the next token prediction looks like this:
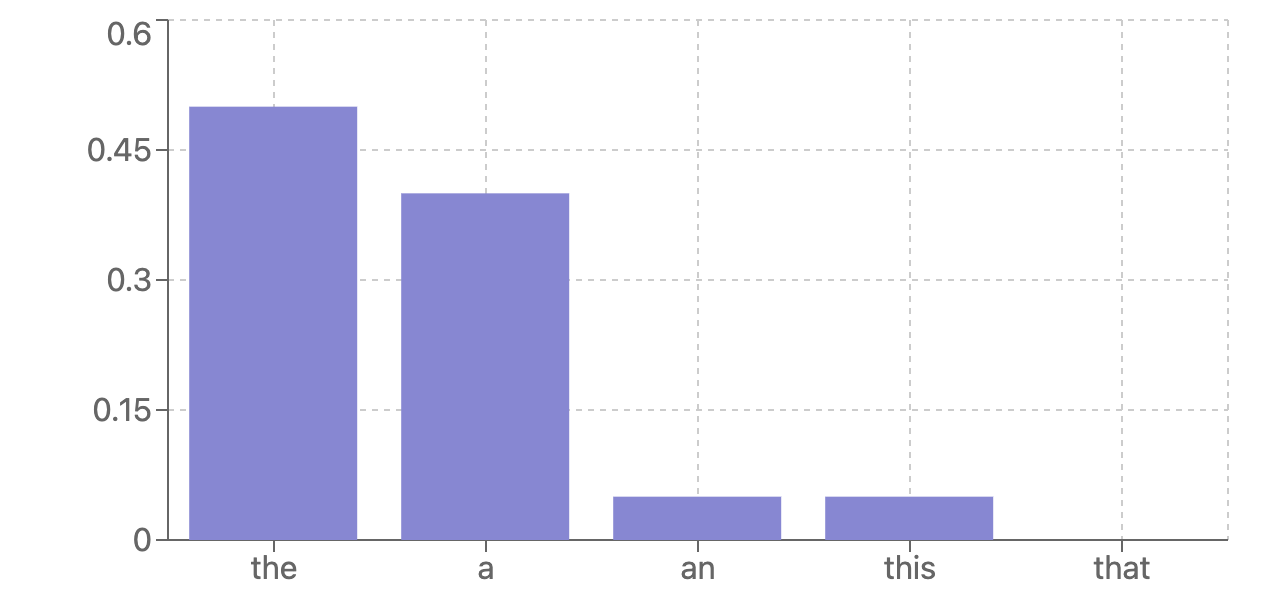
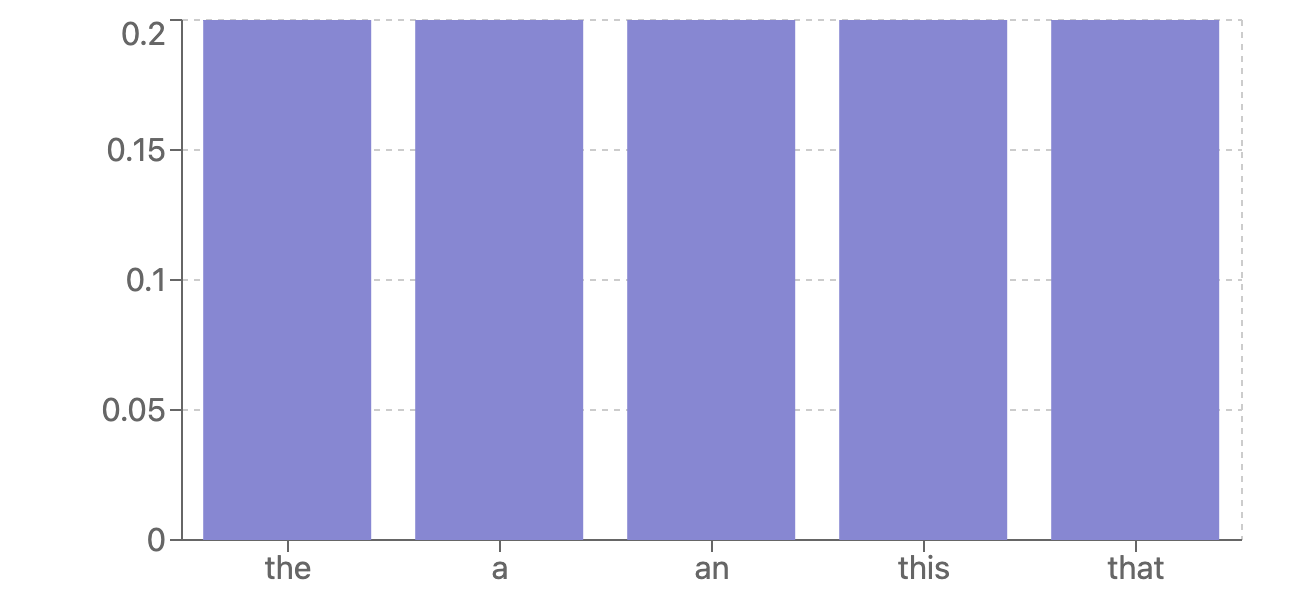
In these cases, the model is uncertain.
Entropix is a method for using adaptive sampling to make better decisions when the model is uncertain.
What does uncertainity mean, and does it matter?
This uncertainty in the logits might have many different underlying causes, and not all are bad.
Causes include:
- The tokens are synonyms or equivalent (e.g. good vs great)
- There are branching paths (e.g. the AI could either write your program in Java or C)
- The AI may genuinely not be sure what to do (it is ‘out of distribution’, it hasn’t seen this in its training data before).
Entropix suggests that you should have different methods for choosing the next token, depending on how uncertain you are.
How do we do that? To start, we need to measure uncertainty.
Entropy and Varentropy
The key tools that Entropix uses are two metrics that measure uncertainty: the entropy & varentropy of the logits.
Entropy measures how different the predicted logits are from each other, i.e. how uncertain we are in the most probably outcome. In low entropy, we are pretty certain in a few of the logits. In high entropy, the distribution of the logits is more uniform and we are much less certain.
Varentropy is a different type of entropy metric. It gives us an idea of the “shape” of the uncertainty. High varentropy indicates that some of the values are highly different from others.
Entropy & Varentropy are based on the idea of surprisal.
Surprisal, also known as self-information, measures how unexpected or surprising an event is based on its probability. For an event x with probability P(x), the surprisal is:
The more unlikely an event is, the higher its surprisal. For example, if P(x) = 1/8, the surprisal is 3 bits, while if P(x) = 1/2, the surprisal is only 1 bit.
Entropy is the expected value (weighted average) of surprisal across all possible outcomes.
Varentropy is calculated as the variance of the surprisal:
High varentropy indicates that some of the values are highly different from others - in other words, some outcomes are much more surprising than others relative to the average surprisal (entropy).
Combined, the two of us give 4 possible states:
- Low entropy, low varentropy: A very peaked distribution (one highly probable outcome).
- Low entropy, high varentropy: A distribution with a few disparate peaks.
- High entropy, low varentropy: A uniform or near-uniform distribution.
- High entropy, high varentropy: A spread-out but uneven distribution.
Adaptive Sampling based on Entropy & Varentropy
Now that we have those metrics for uncertainty, we can use them to perform different types of sampling based on the situation.
Low Entropy, Low Varentropy
This is usually the ideal case. The model is certain not only in what its first option would be, but also what it would choose if the first option was incorrect. Often times this means that the list is ordered in a neat way.
In this case, adaptive sampling would suggest the standard argmax sampling, e.g. choose the token with the highest probabilitly.
Low Entropy, High Varentropy
In this case, the model predicts a few options very highly.
This is a tricky case- it may be representing a whole new branch of output, or it may be representing a few options such as a synonym.
In this case, we may want to “branch” by predicting both logits, seeing what paths they take and comparing the results after some point. There are many ways to implement this branching, which deserves its own post.
Depending on the results of the branching, we could take different actions. If we get two branches with fairly equal confidence (as measured by their entropy and varentropy) but with different contents, we could formulate this as a question to the user.
High Entropy, Low Varentropy
This state represents a possible low confidence state in the model. It may be seeing something that it doesn’t recognize at all, or all the options may be interchangeable with each other.
The best thing to do here is to help the model get to a higher confidence state. Entropix suggests using a “thinking” token here as the next token, e.g. “Wait..”
A thinking token is a token that we insert into the output, to make the model realizes it needs to spend more compute time thinking about the answer before giving one.
For example, if the model is predicting “The capital of Germany is Paris” but it is not sure about the answer, it might insert a thinking token and predict “The capital of Germany is Paris… Wait, no, it’s actually Berlin”
High Entropy, High Varentropy
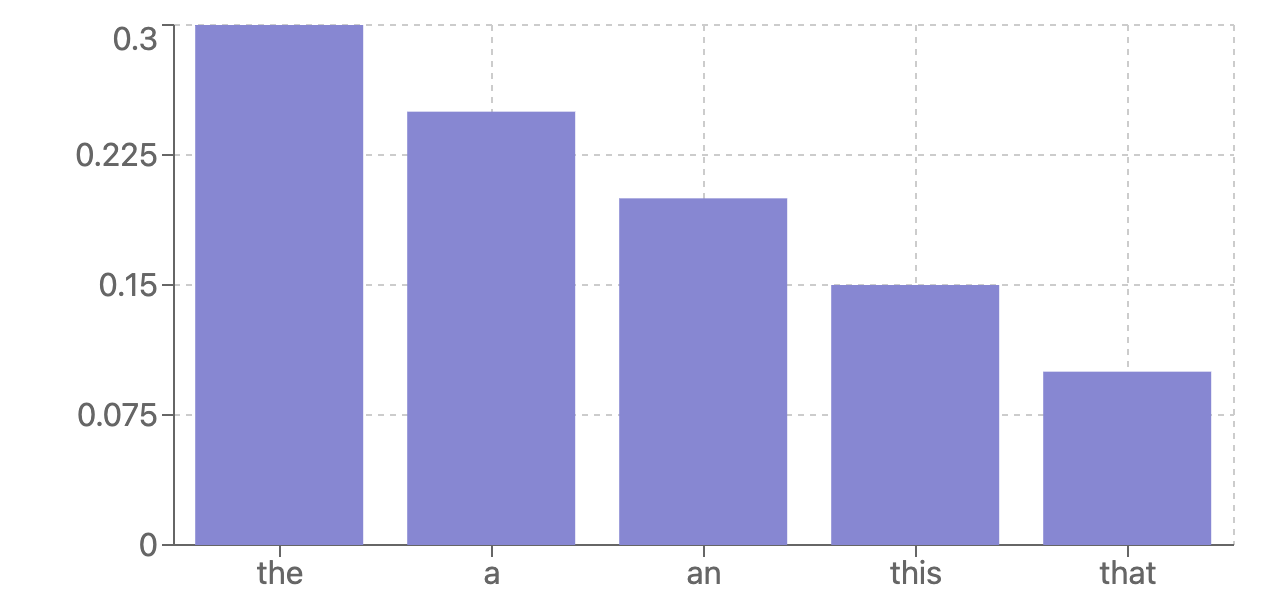
The model has no clear favorite, but it is more certain in some outputs than others. This is a difficult place to be in. One way to think about is that any of the top options may be solid choices (e.g. they are synonyms to each other), and so we should just choose one at random (aka a higher temperature).
We could also branch, or insert thinking tokens like we have done in previous options.
Branching vs Thinking Tokens
Branching & thinking tokens are two different ways of achieving more compute in an uncertain state.
Branching predictions involves following a few logits to see what other tokens they lead to. This is often called MCTS (Monte Carlo Tree Search) and is a method that has been often tried in LLMs to middling success. One of the tradeoffs of branching is that it requires using inference compute in a way where the branches cannot benefit from each others compute.
Thinking tokens are a way of achieving more compute in an uncertain state without sacrificing some of that compute to explore a branch that you might kill. Inserting “Wait…” causes the AI to realize that it might have made a mistake.
Branching vs thinking tokens is overall an open research question, and deserving of another post.
Attention Entropy
It’s worth noting that there are other measures of entropy that we might take into account. Entropix uses them slightly to figure out how to modify temperature, but they might be other tools.
Attention Entropy - How much are your attention heads tend to follow specific tokens, vs pay attention to a large number of tokens in the context.
Attention Agreement - How much your attention heads are paying attention to the same tokens as each other, vs different ones.
If your heads have low entropy and high agreement, that can be another signal for you to be confident sampling the highest probability. Low agreement might indicate that different heads are contributing to different predictions, and it might be worth branching.
Does this matter?
The insights in Entropix feel in many ways fairly easy to understand, and not entirely novel, which has been surprising to many.
Even if the evals don’t show a large benefit yet. But, inference-time techniques like this are easy to experiment with and could be a promising direction for open source hackers to improve reasoning without huge budgets.